
Comfy UI
El mejor sistema local y abierto

Recuerdo cuando descubrí ComfyUI. Sería a finales de 2023 o principios de 2024. Veníamos de una etapa realmente dura para la industria de los VFX, después de las huelgas de actores y guionistas que habían paralizado prácticamente toda la producción durante casi un año.
Yo ya llevaba un tiempo experimentando con herramientas de IA generativa. Midjourney en Discord me tenía completamente atrapado. Luego montaba los vídeos con Runway o Pika, pero no me daba la pasta para pagar 60/80 pavos al mes en suscripciones. No había casi curro...
Por ahí andaba Automatic 1111, donde se podían correr los primeros modelos open source de Stable Diffusion. Molaba y era gratis, pero los resultados no se acercaban ni de lejos a los de Midjourney.
Supongo que navegando por foros buscando información sobre este mundo, caí en Comfy. De aquellas, la instalación era un auténtico horror (sobre todo para los que no nacimos bendecidos con el don de la paciencia para aprender programación). Yo intentaba aprender Python, sin mucho éxito. Menos mal que ya podía contar con ChatGPT para resolver cada problema que me iba encontrando: las malditas dependencias... Instalaba Comfy, y de repente me dejaban de funcionar los otros siete programas que tenía en el ordenador. Iba completamente a ciegas.
No se la de horas que puede pasar resolviendo problemas técnicos hasta generar mi primera imagen... Pero había algo en Comfy que era para mi. El sistema de nodos, yo vengo de pasar los últimos 15 años día a día delante de un sistema de nodos como es Nuke así que pensé si hay algo en la IA en lo que parto con ventaja es aquí.
Siempre he sido de los que piensan que lo realmente importante en nuestra profesión es la imagen final, el visor. Me da igual si está resuelta con siete nodos básicos o con 57 gizmos llenos de expresiones en cada valor. Eso no es lo importante.
Durante el tiempo que pasaba en Comfy, el 95 % era para resolver errores de código, otro 4 % esperando a que se generara la imagen (todo era local), y el último 1 % valorando el resultado.
Mal negocio. Aquello tenía un potencial brutal —se veía a la legua—, pero le faltaba desarrollo. Así que decidí dejarlo respirar por un tiempo.
Diría que volví en serio casi un año después, las cosas habían cambiado..
Comfy Org estaba empezando a crecer tomando una estructura mas empresarial y poniendo las cosas más fáciles a los usuarios. En Septiembre de 2025 levantó una ronda financiación de 17 millones de dólares que se deberían traducir en nuevas funcionalidades y un entorno mas user friendly.
Ahora si, empecemos por lo básico:
Es muy tentador bajarse templates y empezar a tocar nodos y parámatros sin tener la menor idea de lo que estamos haciendo, normal así hemos empezado todos. Pero pienso que los concpetos básicos son la clave de todo, los modelos irán cambiando, unos generan hype otros darán resultados burtales pero como funiona comfy o la generación de imagenes con IA es lo mas importante.
Así que nada, vamos a ello.
Voy a hablaros de los elementos clave para generar una imagen en Comfy a partir de texto. Text-to-image, el workflow más básico del que podemos partir:
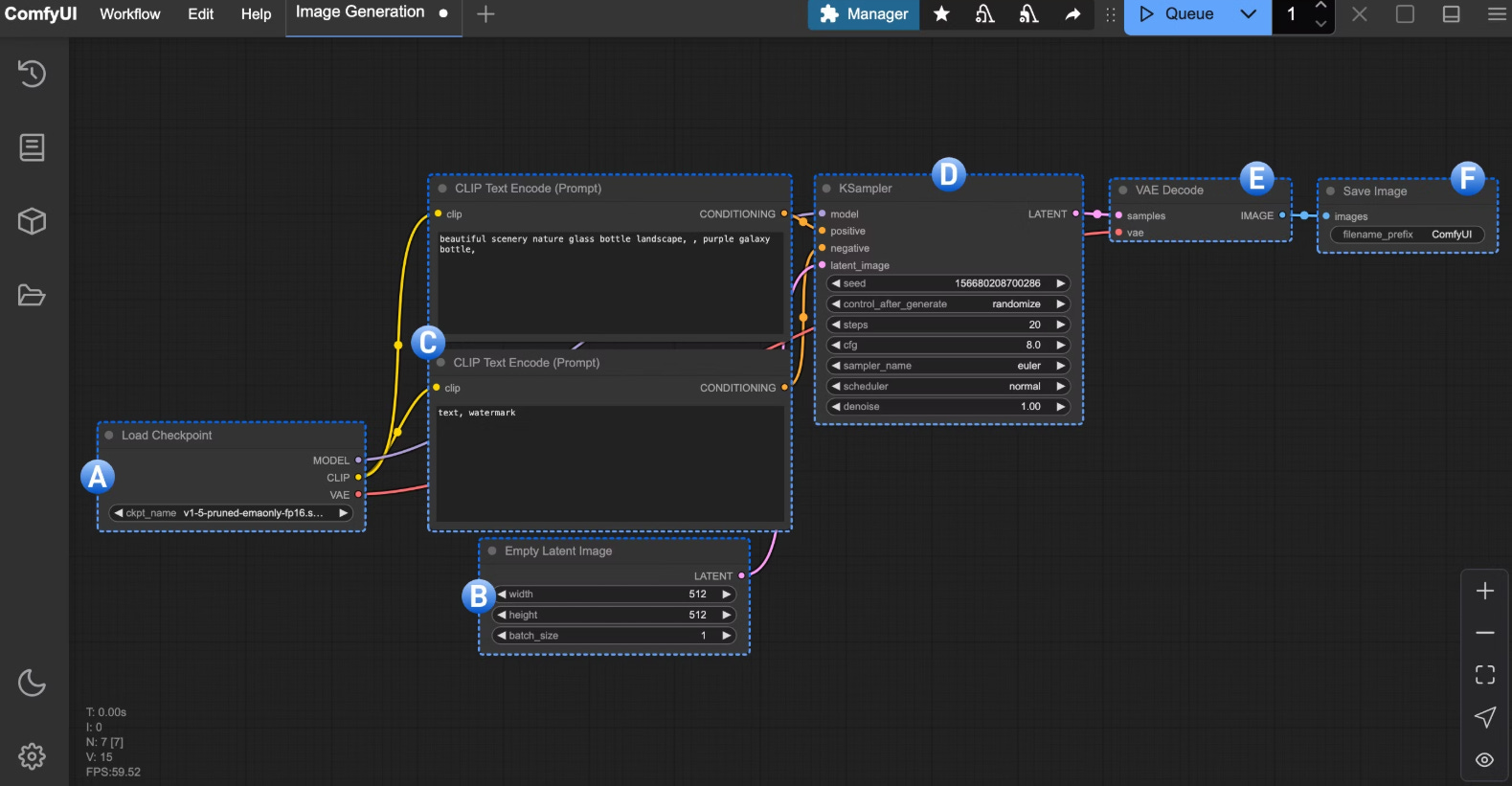
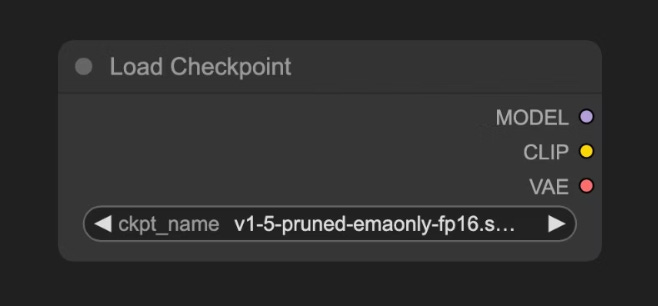
A - MODELO DE DIFUSIÓN:
Es el “artista”. Cargaremos este modelo con el nodo “Load Checkpoint”. Lo que estamos haciendo es llamar a un punto del entrenamiento con un archivo .ckpt o .safetensors que contiene los parámetros aprendidos.
Se llaman modelos de difusión porque aprenden a invertir el proceso de difusión del ruido, es decir, a transformar ruido aleatorio en una imagen coherente eliminando ese ruido paso a paso.
Este archivo suele tener embebidos tres componentes:
Modelo (UNet): Es el encargado de predecir el ruido y generar la imagen durante el proceso de difusión.
Clip: Es el codificador de texto que convierte nuestras indicaciones (text prompts) en vectores numéricos que el modelo puede entender.
VAE (Variational AutoEncoder): Convierte las imágenes entre el espacio de píxeles y el espacio latente, ya que los modelos de difusión trabajan en el espacio latente, mientras que nuestras imágenes existen en el espacio de píxeles.
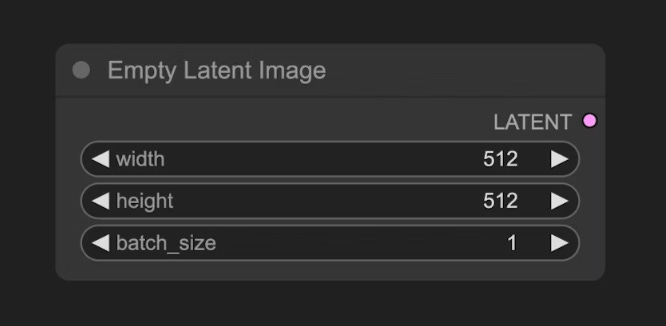
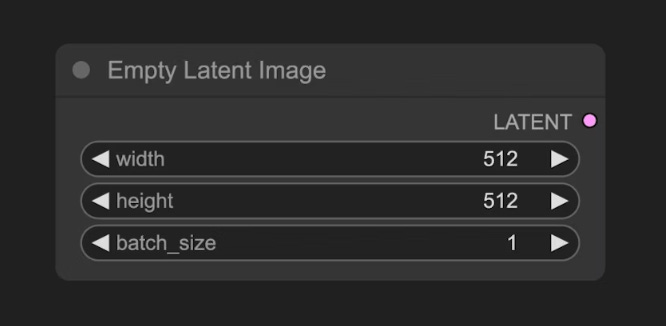
B - ESPACIO LATENTE:
Un canvas abstracto. Definiremos los parámetros del lienzo con el nodo “Empty Latent Image”. Cuando trabajamos con modelos de difusión estos operan en el espacio latente. No hay que pensar en un espacio visualmente entendible por nosotros como son los píxeles si no en otro espacio con una representación matemática más compacta y semántica de la imagen.
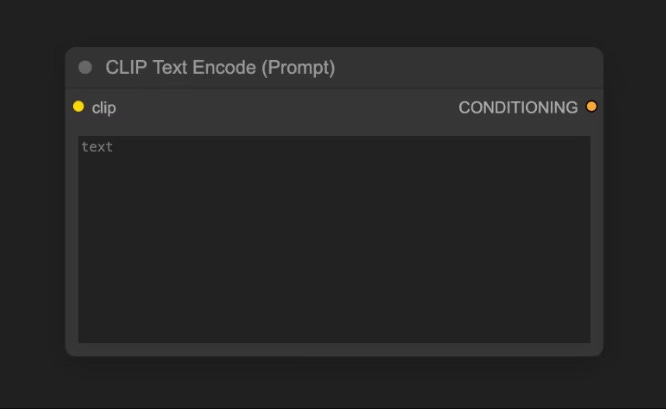
C - CLIP TEXT ENCODE:
Aquí es donde le daremos las instrucciones al artista. Escribiremos nuestro promt dentro del nodo “Clip Text encode” en lenguaje natural, tanto positivas como negativas. Los prompts se codifican en vectores semánticos mediante el componente CLIP cargado desde el Checkpoint .

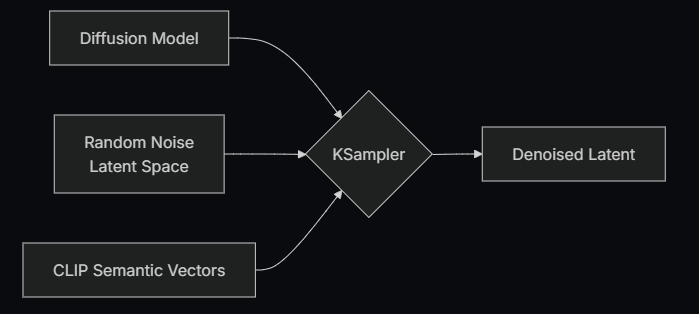
D - K SAMPLER:
Es el núcleo de todo el flujo de trabajo, donde ocurre todo el proceso de eliminación del ruido, produciendo finalmente una imagen en el espacio latente.
En el nodo KSampler, el espacio latente utiliza la semilla (seed) como parámetro de inicialización para construir el ruido aleatorio, y los vectores semánticos Positive y Negative se introducen como condiciones para el modelo de difusión.
Luego, según el número de pasos de eliminación de ruido especificado por el parámetro steps, se realiza el proceso de denoising. Cada paso de denoising utiliza el coeficiente de intensidad de eliminación de ruido definido por el parámetro denoise para limpiar el espacio latente y generar una nueva imagen en el espacio latente.
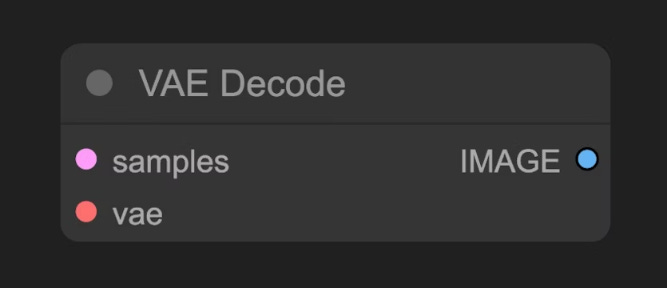
E - VAE Decode:
Sería nuestro render. Es el punto en el que convertimos la imagen generada en el espacio latente a píxeles. Por un lado llamamos a los samples o datos generados por el K-Sampler y por otro lado al entrenamiento de este decodificador embebido en el modelo.
F - SAVE IMAGE:
Es el proceso donde podemos por fin visualizar una nuestra imagen en formato de píxleles y guardarla como .jpg, png...
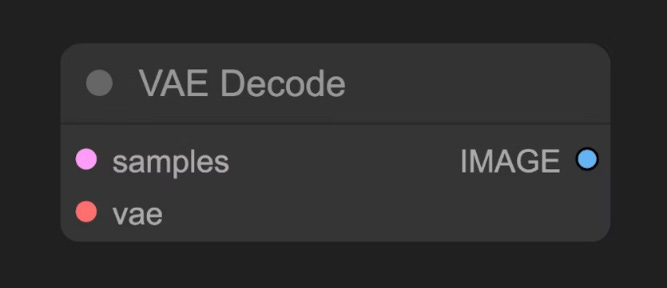
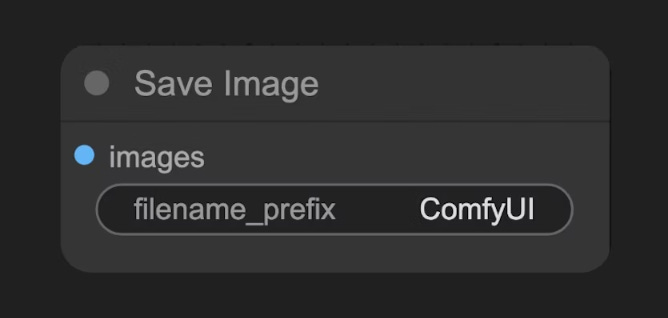
Cada uno de estos elementos merece un post específico, pero creo que es una buena introducción a como gestiona Comfy el proceso de generación de una imagen.
Seguiremos hablando desde un punto de vista teórico y poco a poco nos iremos manchando las manos y poniéndolo en práctica.
Seguimos! Feliz semana a todos!